
Table of contents
Setup (Docker)
- Pull the Postgres Docker Image
Loading code...
- Run the Postgres Docker Container
Loading code...
- Start the psql command-line interface
Loading code...
Databases and Tables
Creating a Database
Loading code...
- Listing Databases: \l
- Connecting to a Database: \c company
Dropping a database
Loading code...
Creating a Table
Loading code...
Loading code...
Table Constraints
Constraints enforce rules for the data in a table. Common constraints include:
- PRIMARY KEY: Uniquely identifies each row in a table.
- FOREIGN KEY: Ensures referential integrity between tables.
- UNIQUE: Ensures all values in a column are unique.
- **NOT NULL:**Ensures a column cannot have a NULL value.
- CHECK: Ensures values in a column meet a specific condition.
- Default Constraint: Assigns a default value to a column if no value is specified when a row is inserted.
Dropping Constraints
Loading code...
ALTER TABLE
Loading code...
Loading code...
Dropping a table
Loading code...
INSERT
Loading code...
Loading code...
UPSERT
UPSERT, a combination of "INSERT" and "UPDATE".
If an employee's email already exists, update the salary, department_id, and additional_info.
Loading code...
If an employee’s email already exists, do nothing.
Loading code...
Update only if the new salary is higher than the existing one.
Loading code...
Key Points
- Conflict Target: Specify which column(s) to check for conflicts. It must be a unique or primary key constraint.
- EXCLUDED Keyword: Refers to the row proposed for insertion that caused the conflict.
- Conditional Logic: You can apply conditional logic in the DO UPDATE clause to handle conflicts more intelligently.
Using COPY for Bulk Inserts
Loading code...
Loading code...
SELECT
Loading code...
- ->: Extracts a JSON object field or array element.
- ->>: Extracts a JSON object field or array element as text
- @>: Checks if a JSON object contains another JSON object or if a JSON array contains a specified element.
- ||: The concatenation operator, used here to append the new element to the existing array.
Using CASE with SELECT
Loading code...
Sorting Results
Loading code...
Limiting Results
Loading code...
Subqueries
Subqueries in SELECT
Loading code...
Subqueries in WHERE
Loading code...
Correlated Subqueries
Loading code...
Scalar Subqueries
Loading code...
UPDATE
Loading code...
Loading code...
Loading code...
- jsonb_set updates a specific key within the JSONB column
- The path '{hobbies}' specifies that we are updating the hobbies array.
- The additional_info->'hobbies' || '"cycling"' concatenates the existing hobbies with the new hobby "cycling".
- true: A boolean flag indicating whether to create the key if it does not exist.
Loading code...
DELETE
Loading code...
Referential Actions
CASCADE is used in two contexts:
- ON DELETE CASCADE: Automatically deletes all child records when a parent record is deleted.
- ON UPDATE CASCADE: Automatically updates all child records when a parent record is updated.
Drop the existing foreign key constraint:
Loading code...
Add the new foreign key constraint with ON DELETE CASCADE and ON UPDATE CASCADE:
Loading code...
- If a department is deleted from the departments table, all employees in that department (in the employees table) are automatically deleted as well.
Loading code...
- In this case, deleting a department sets the department_id in the employees table to NULL instead of deleting the rows.
Loading code...
- If a department's department_id is updated in the departments table, the department_id in all related employees records is automatically updated to match the new department_id.
Loading code...
Relationships
One to One
Each row in one table is linked to one and only one row in another table. The foreign key in one table (usually the child) also has a unique constraint, ensuring that each value appears only once in this column.
Loading code...
The user_profiles table has a user_id column that references the users table. The UNIQUE constraint on user_id in user_profiles ensures a one-to-one relationship. Each user can have only one profile, and each profile is linked to only one user.
One to Many
A single row in the parent table can be linked to multiple rows in the child table. The foreign key in the child table does not have a unique constraint, allowing multiple rows to reference the same row in the parent table.
Loading code...
Many to Many
Loading code...
Loading code...
Loading code...
JOIN

Inner Join
Combines rows from two tables based on a condition, and returns rows where the condition is true.
Loading code...
Left Join (or Left Outer Join)
Returns all rows from the left table and matched rows from the right table. If no match is found, NULL is returned for columns of the right table.
Loading code...
Right Join (or Right Outer Join)
Returns all rows from the right table and matched rows from the left table. If no match is found, NULL is returned for columns of the left table.
Loading code...
Full Join (or Full Outer Join)
Returns rows when there is a match in one of the tables. If there is no match, NULLs are returned for non-matching rows from both tables.
Cross Join
Returns the Cartesian product of the two tables, i.e., each row from the first table is combined with all rows from the second table.
Self Join
A table is joined with itself. Useful for hierarchical data or when comparing rows within the same table.
Natural Join
A type of join that automatically joins tables based on columns with the same name. Be cautious as it might not always produce the desired results.
List all employees, their departments, and the projects they are involved in.
Loading code...
List all employees and the projects they are working on.
Loading code...
CTE
A Common Table Expression (CTE) is a temporary result set that you can reference within a SELECT, INSERT, UPDATE, or DELETE statement.
Loading code...
Loading code...
Aggregation
- COUNT():Counts the number of rows or non-NULL values.
- SUM(): Calculates the total sum of a numeric column.
- AVG(): Calculates the average value of a numeric column.
- MIN(): Finds the minimum value in a column.
- MAX(): Finds the maximum value in a column.
In SQL, any column in the SELECT clause that is not part of an aggregate function must also be included in the GROUP BY clause.
- Count the Number of Employees in Each Department
Loading code...
- Total Salary by Department
Loading code...
- Count of Projects by Employee
Loading code...
- Average Number of Projects per Employee
Loading code...
- Departments with More than 2 Employees
Loading code...
- Total Salary by Department for Employees with Specific Skills
Loading code...
SQL Query Execution Order
- FROM Clause
- JOIN Clause
- ON Clause
- WHERE Clause
- GROUP BY Clause
- HAVING Clause
- SELECT Clause
- ORDER BY Clause
- LIMIT Clause
Views
views are virtual tables that allow you to save complex queries for later use
Loading code...
Loading code...
Materialized Views
Materialized views store the query results physically on disk. They improve performance by eliminating the need to re-execute complex queries every time data is accessed.
Loading code...
Loading code...
Loading code...
Loading code...
Comparing Materialized Views and Regular Views
| Aspect | Materialized View | Regular View |
|---|---|---|
| Storage | Physically stores query results. | Stores only the query definition. |
| Performance | Faster for complex queries, read-intensive. | Slower for complex queries, as the query runs each time. |
| Data Freshness | Needs manual or scheduled refresh. | Always current (real-time). |
| Use Case | Frequent reads, less frequent updates. | Dynamic data where real-time results are necessary. |
Function
Loading code...
Loading code...
Loading code...
- $$ is called "dollar quotes".
- This language is called PL/pgSQL. It's a very SQL like language designed to be easy to write functions and procedures. PostgreSQL actually allows itself to be extended and you can use JavaScript, Python, and other languages to write these as well
Functions triggers
Loading code...
Create the Trigger Function
Loading code...
Create the Trigger
Loading code...
Test the Trigger
Loading code...
- Trigger Function: log_employee_deletion captures the deleted record details and inserts them into the recycle_bin table.
- Trigger: employee_deletion_audit is triggered before a DELETE operation on the employees table and calls the log_employee_deletion function.
- Recycle Bin Table: Stores the deleted employee records along with the timestamp and action details.
Procedures
Procedures in PostgreSQL are similar to functions but are designed for executing a sequence of SQL statements, and unlike functions, they do not return a value.
Loading code...
You use CALL instead of SELECT to invoke procedures. Note you can't run procedures as triggers. Triggers always deal with functions. However there's nothing preventing you from CALLing a procedure from a function.
Loading code...
Window Functions
- ROW_NUMBER(): Assigns a unique number to each row.
Loading code...
- RANK(): Assigns a rank to each row within the partition of a result set.
Loading code...
- DENSE_RANK(): Similar to RANK(), but without gaps in ranking.
- SUM(): Calculates the sum of values.
Loading code...
- AVG(): Calculates the average of values.
- MAX(): Finds the maximum value.
- MIN(): Finds the minimum value.
- LAG(): Accesses data from a previous row.
Loading code...
- LEAD(): Accesses data from a subsequent row
Loading code...
Frame Specification
Loading code...
Transactions
ACID Properties:
-
Atomicity: Transactions should be like a single, unbreakable action. Everything inside a transaction should succeed or fail together, so we don't end up with partial changes that mess things up.
-
Consistency: Transactions keep the database in a good, consistent state. For example, if we add an order, we also need to add the items for that order to keep things sensible.
-
Isolation: Transactions should happen in their own little world, so they don't mess each other up. Each transaction should wait its turn to make changes and not interfere with others.
-
Durability: Once a transaction is done, its changes should stick around even if something bad happens like a power outage or a system crash.
Loading code...
Rollback if there's an issue:
Loading code...
Database Transactions and Concurrency
Indexing
EXPLAIN Cost
The costs are in an arbitrary unit. A common misunderstanding is that they are in milliseconds or some other unit of time, but that’s not the case.
Startup Costs
The first numbers you see after cost= are known as the “startup cost”. This is an estimate of how long it will take to fetch the first row. For a sequential scan, the startup cost will generally be close to zero, as it can start fetching rows straight away. For a sort operation, it will be higher because a large proportion of the work needs to be done before rows can start being returned.
Loading code...
In the above query plan, as expected, the estimated statement execution cost for the Seq Scan is 0.00, and for the Sort is 66.83.
Total Costs
The second cost statistic, after the startup cost and the two dots, is known as the “total cost”. This is an estimate of how long it will take to return all the rows.
We can see that the total cost of the Seq Scan operation is 17.00. For the Sort operation is 69.33, which is not much more than its startup cost (as expected).
EXPLAIN ANALYZE
Loading code...
We can see that the total execution cost is still 69.33, with the majority of that being the Sort operation, and 17.00 coming from the Sequential Scan. Note that the query execution time is just under 21ms.
Types of Indexes
- Primary Index: Created automatically on the primary key column. Ensures unique and non-null values.
- Unique Index: Ensures that all values in the indexed column(s) are unique.
Loading code...
Loading code...
Creating Index
Loading code...
| Index Type | When to Use | Advantages | Disadvantages |
|---|---|---|---|
| B-tree | Equality and range queries, ordering | General-purpose, efficient | Maintenance overhead |
| Hash | Exact match queries | Fast exact match lookups, space-efficient | Not suitable for range queries |
| Bitmap | Low cardinality columns, complex queries | Space-efficient for low cardinality, efficient for complex queries | Not suitable for high cardinality, maintenance cost |
| GiST | Non-standard data types, custom queries | Flexible, handles complex data types | Complexity |
| GIN | Full-text search, composite types | Efficient for full-text and array queries | Large index size, maintenance |
| SP-GiST | Spatial, multidimensional queries | Efficient for spatial data | Complexity |
| Full-Text | Text search in large documents | Improves text search performance | Large storage space, setup complexity |
| Clustered | Primary keys, range queries, sorting | Fast access based on ordering key | Only one per table, costly reordering |
| Non-Clustered | Secondary keys, frequently queried columns | Flexible, multiple indexes per table | Additional storage, pointer lookups |
Loading code...
Loading code...
GIN and Full Text Search
GIN is good for things where you can have one column that have multiple values that can return true. So what if we took our search term (in this case let's search for senior software engineer) and broke it down in smaller, searchable pieces? Like, three letter pieces, or as they're called, trigrams. This is one way PostgreSQL can handle full text search.
Loading code...
Loading code...
Loading code...
Loading code...
Loading code...
CREATING INDEX
Loading code...
Loading code...
Loading code...
Partial indexes
Loading code...
Creating Index
Loading code...
Database design
Data Modeling
- Conceptual Model:
- Purpose: Shows the main entities and their relationships.
- Example: Student and Course entities. A student enrolls in a course.
- Used For: Talking with business people to understand what data is needed.
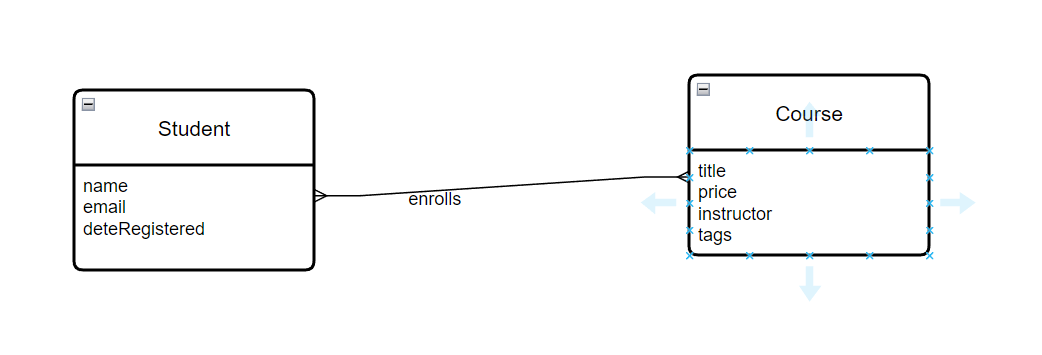
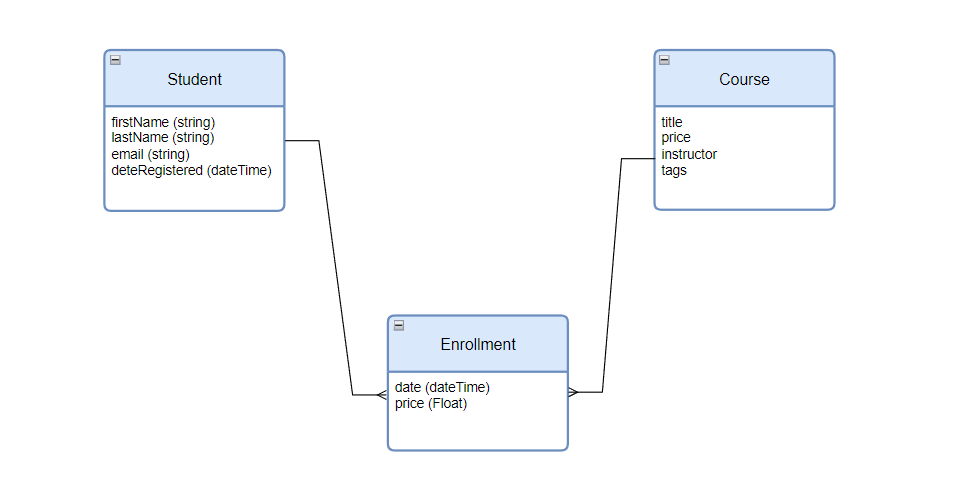
- Logical Model:
- Purpose: Details the structure of data, including attributes.
- Example: Student table with attributes like first_name, email. Enrollment date should be part of the Enrollment table, linking Student and Course.
- Used For: Planning how to store data without worrying about the specific database.
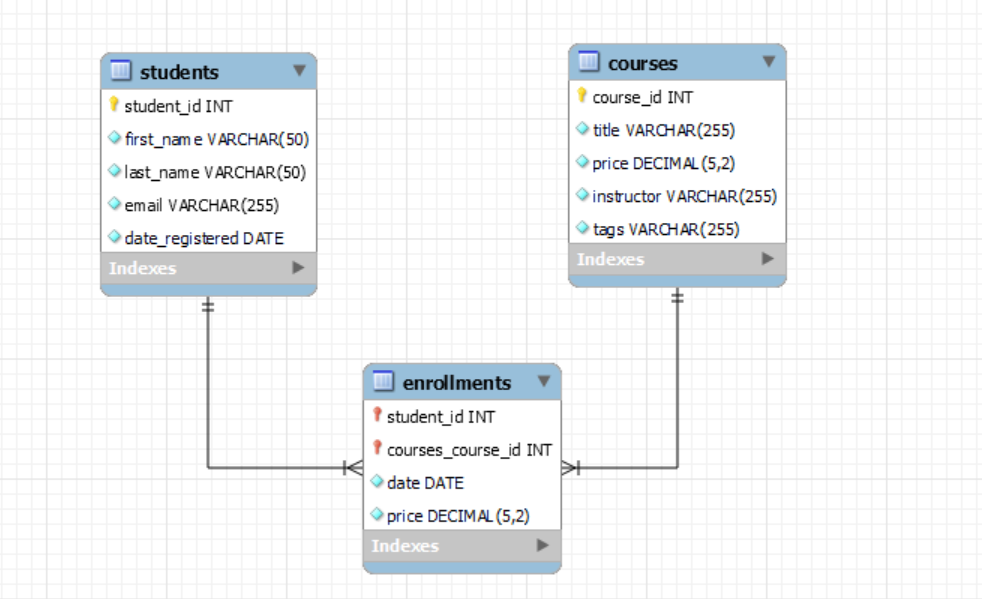
- Physical Model:
- Purpose: Converts the logical model into tables with keys and data types for a specific database.
- Example: students, courses, and enrollments tables with actual data types and keys.
Database Keys and Constraints
- Primary Key: Unique identifier for each record.
- Foreign Key: A key in one table that links to a primary key in another table.
- Foreign Key Constraint: Ensures that the foreign key value exists in the referenced table.
Normalization
- First Normal Form (1NF): Each cell should have a single value; no repeating groups. Example: students table with single-value fields.
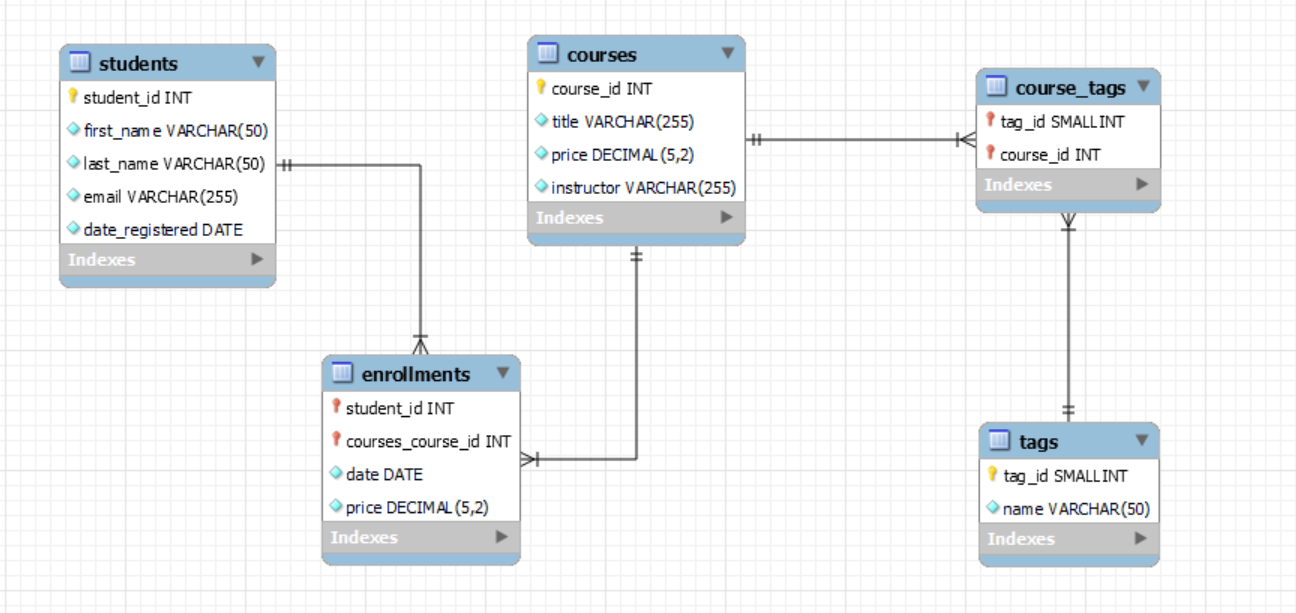
- Second Normal Form (2NF): The table should describe one entity, and each column should relate to that entity; no partial dependency. Example: enrollments table attributes like date and price depend on both student_id and course_id.
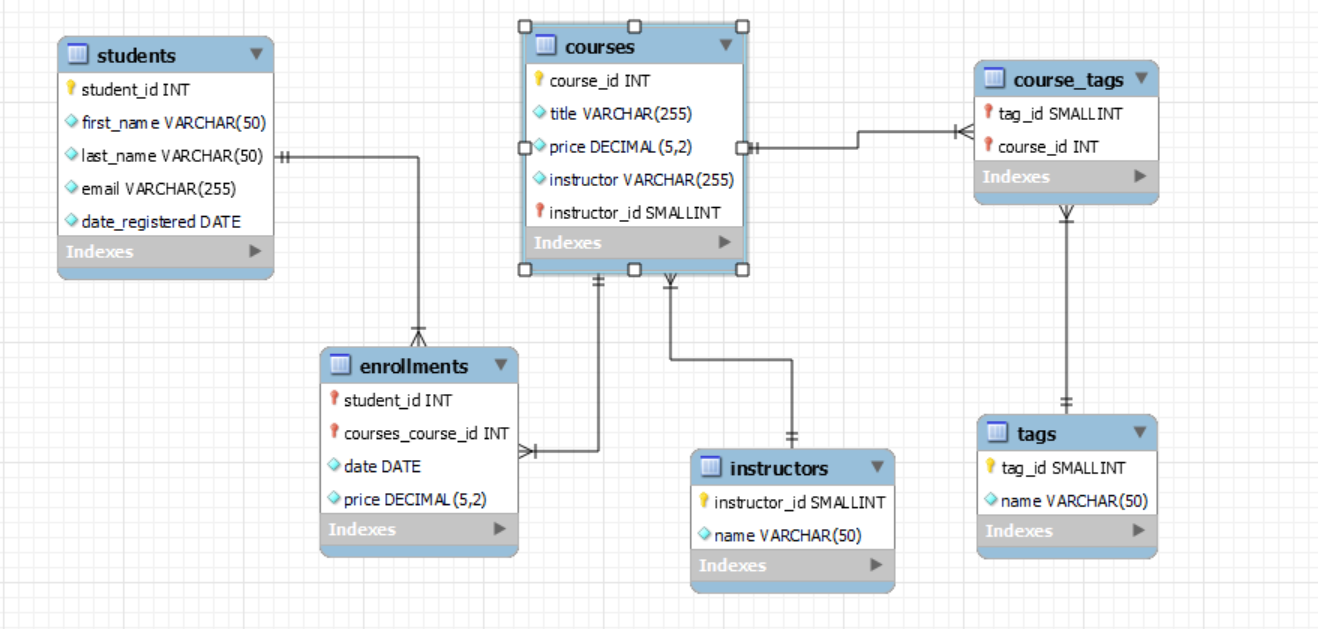
- Third Normal Form (3NF): No column should depend on another non-key column. Example: Avoid storing derived or calculated data in a table.